Den modellen finns tillgänglig via verktyget Transkribus.
Läs här om hur du använder Transkribus och får hjälp med dina svårtolkade texter.
Transkribus är en webbapplikation skapad av en österrikisk kooperation “Read-Coop” med över 150 medlemmar såsom universitet, arkivinstitutioner, bibliotek med flera från över 30 olika länder.
Webbtjänsten är under utveckling och fungerar för närvarande bäst i Google Chrome, men Windows Edge eller Macens standardwebbläsare går också bra.
HTR - Handwritten text recognition fritt översatt blir det, handskriven texttolkning.
Modell - Ett program som har tränats på en uppsättning data för att känna igen vissa mönster eller fatta vissa beslut utan ytterligare mänsklig inblandning. I det här fallet har det tränats på dokumentbilder.
Riksarkivet i Sverige har skapat modellen “The Swedish Lion” den AI-modellen kan tolka handskrivna texter på svenska från 1600-, 1700- och 1800-talen och uppnå en imponerande noggrannhetsgrad på 95%. Den har tränats med hjälp av data från texter som omfattar 3,3 miljoner textrader och totalt 15,6 miljoner ord.
Läs mer om Riksarkivets arbete Ny banbrytande AI-modell för svenska historiska texter i pressmeddelande från 2024-02-07
Skapa ett konto i Transkribus
Gå in på www.transkribus.org och klicka på knappen Open app.

Därifrån kan du skapa ett nytt konto.
Du klickar på länken Register längst ned i formuläret Sign in to your accont.

Därefter fyller du i formuläret Register för att registrera dig som användare i Transkribus.
Hur man skapar ett konto och kommer igång finns också beskrivet här: https://help.transkribus.org som också innehåller mer hjälp till hur du hanterar Transkribus.
Det kostar inget att skapa ett eget konto, ladda upp bilder och använda Transkribus för manuell redigering. Däremot tar Transkribus betalt med så kallade ”krediter” när man använder en HTR-modell för att maskinellt texttolka en bild. Varje användare får 100 krediter gratis per månad.
Behöver man mer går det att köpa till fler krediter.
app.transkribus.org
Du arbetar sedan i applikationen app.transkribus.org som du antingen når via samma knapp Open app på Transkribus startsida eller direkt med länken app.transkribus.org
Du loggar in med ditt eget skapade konto med den e-postadress du angav och det lösenord du satte på kontot i formuläret för Sign in to your account.
Transkribus appens startsida ser ungefär ut såhär och innehåller följande.

Home (Hem) - Länk för att komma tillbaka till startsidan i applikationen.
Collection (Samlingar) - Gruppering av ett eller flera dokument i form av olika samlingar med dokument. Mer om Collections nedan.
Tags (Taggar)- Taggar som du kan använda för att markera olika valfria aspekter av ditt dokument för att göra det hanterbart för dig.
Desk - Den här startsidan.
Models - Innehåller det texttolkningsmodeller som finns i Transkribus samt möjlighet att skapa egna modeller (överkurs).
Sites (anläggningar) - Publicerade sajter med transkriberade dokument. Du kan också göra din egen sajt här. (överkurs).
Jobs (Jobb) - Lista med dina beställda serverarbeten och dess status.
Ditt konto (figuren) - Här kan du hantera ditt konto. Här finns också möjligheten att byta språk till svenska. Allt är dock inte översatt, inte heller så bra i vissa fall, så engelska är nästan att föredra.
Förbereda dokument
Skapa Collection
Logga in och skapa en ny Collection (samling) som motsvarar ett arbete som du vill göra, ett projekt eller ett visst arkiv, som kan innehålla flera mappar/volymer med bilder. Det går att byta namn på en Collection efteråt. Man kan också dela sin Collection med andra användare.

Du får namnge din Collection med ett lämpligt beskrivande namn.
Skapa Document
Ladda därefter upp de bilder du vill få transkriberade.
Det går att lägga till fler bilder till din Collection senare.
Du kan antingen lägga till dina bilder direkt eller backa och lägga till bilder vid ett senare tillfälle. Klicka i sådana fall på din Collection och välj Upload Files och ange Document Title.
Document motsvarar en mapp som man samlar bilder under, till exempel en inbunden volym med flera skannade sidor. Det kan vara bilder du fotat av själv, eller bilder från till exempel Riksarkivets söktjänst.
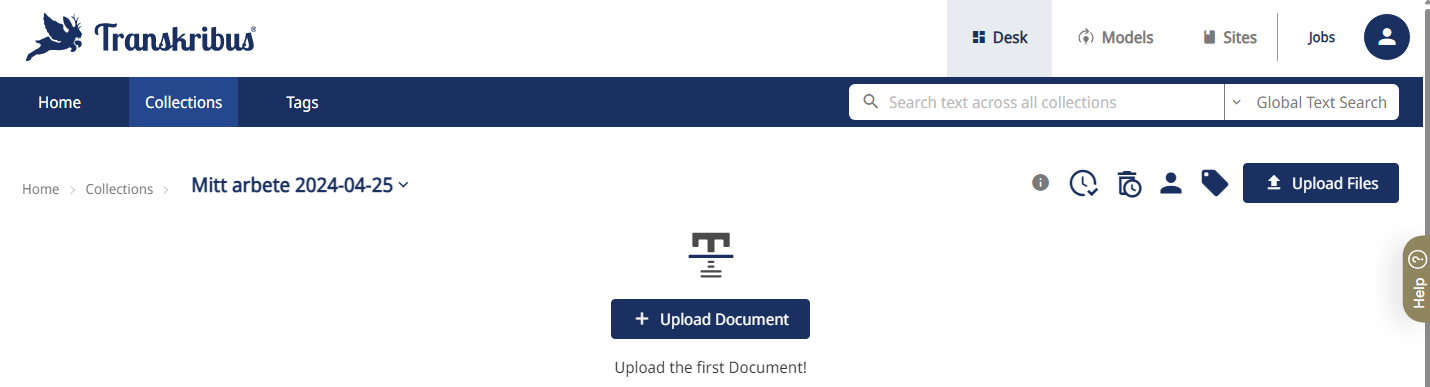
Döper Document med en lämplig titel.

Dokument tillagda som jag vill ha uppladdade.

Klicka på knappen Submit som finns längst ned i fönstret.
I Jobs går det att se att arbetet pågår med uppladdning av dina bilder.

Du kan behöva uppdatera webbsidan (tangent: F5) för att se om uppladdningen eller andra arbeten är färdiga.
Texttolka dokumentbilder
Det är nu det roliga arbetet börjar när du ska börja tolka bildens text. Klicka dig in i din Collection och det Document som du skapat där du laddat upp de bilder du vill arbeta med.
Markera en eller flera bilder genom att klicka i den lilla rutan nedtill vänster vid respektive bild.
Klicka på knappen Recognize som finns ovanför bilderna.
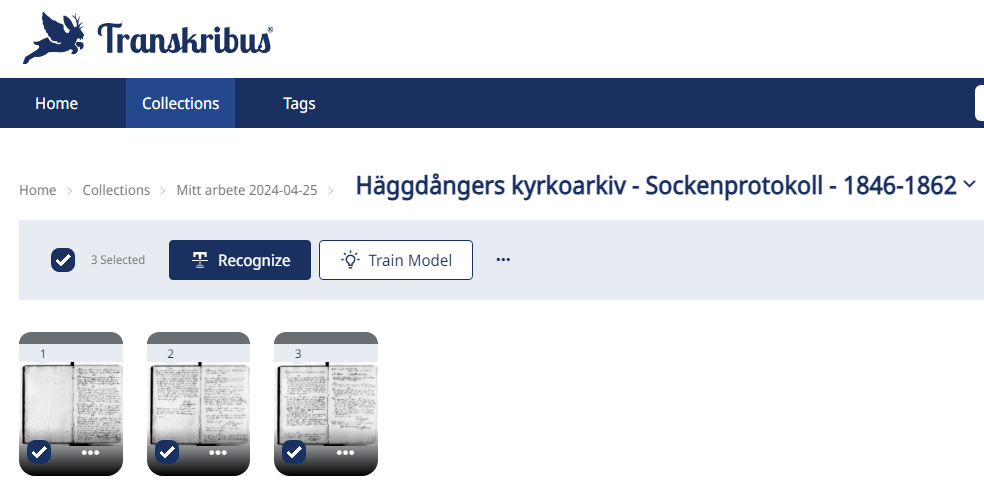
Första gången
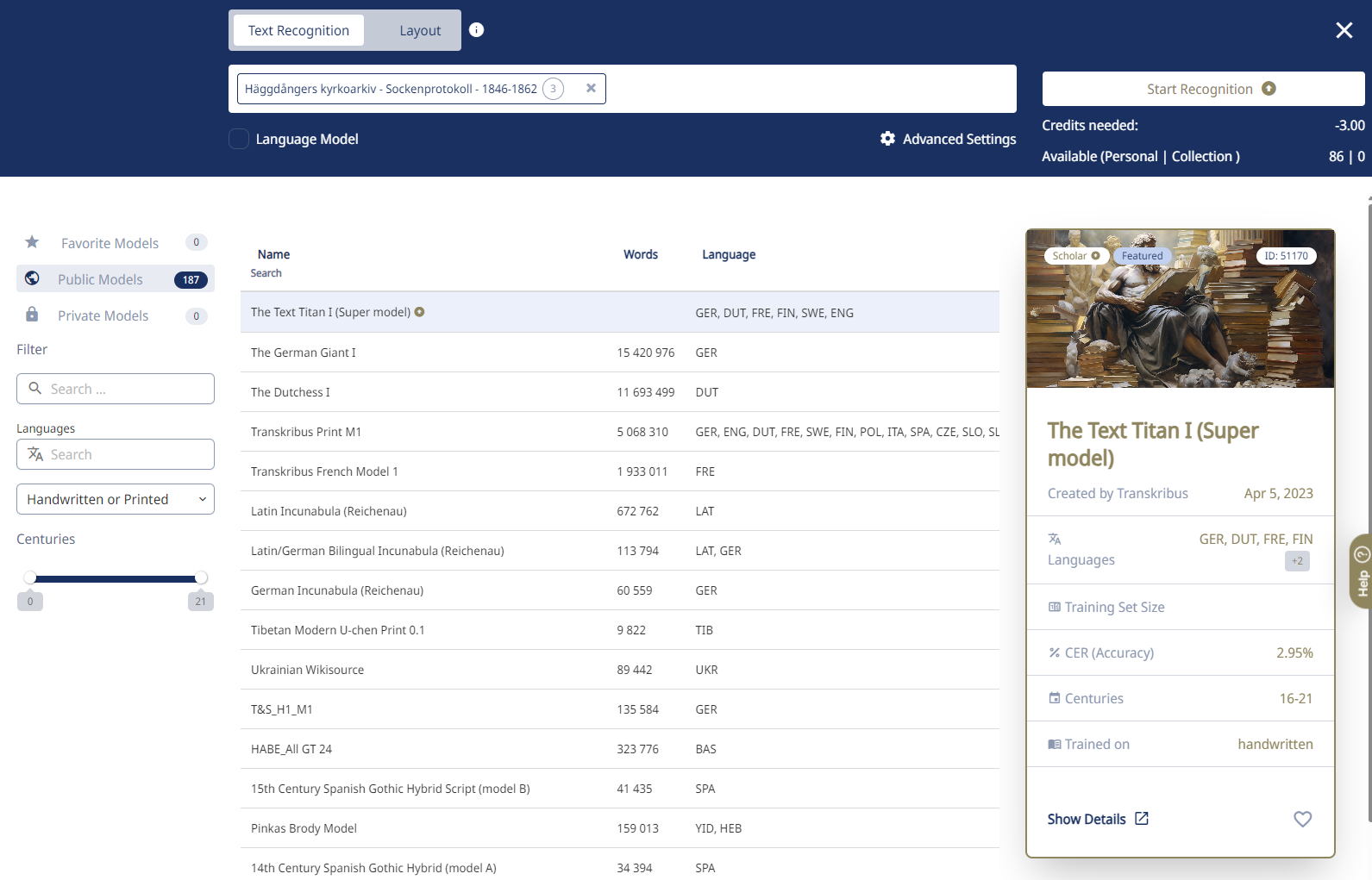
Sök efter “Swedish” eller bläddra i listan bland alla modeller som finns tillgängliga
Markera The Swedish Lion I i listan. Det är den modellen som Riksarkivet har arbetat med att ta fram. Du ser detaljer om vald modell till höger.
Klicka gärna i det lilla hjärtat längst ned till höger i rutan med detaljer om vald modell. På så vis sparar du den modellen som en favorit så att du hittar den lättare nästa gång.

Klicka på Start Recognition uppe till höger.
Det går nu åt en kredit per dokument som du vill ha texttolkad.
Jobs listan dyker upp igen.
Uppdatera sidan för att se status på ditt arbete.
När det är klart (Finished) klickar du på rubriken för ditt arbete och därefter på respektive bild i din Collection, eller klicka på de tre prickarna ute till höger under rubriken Action och välj Open.
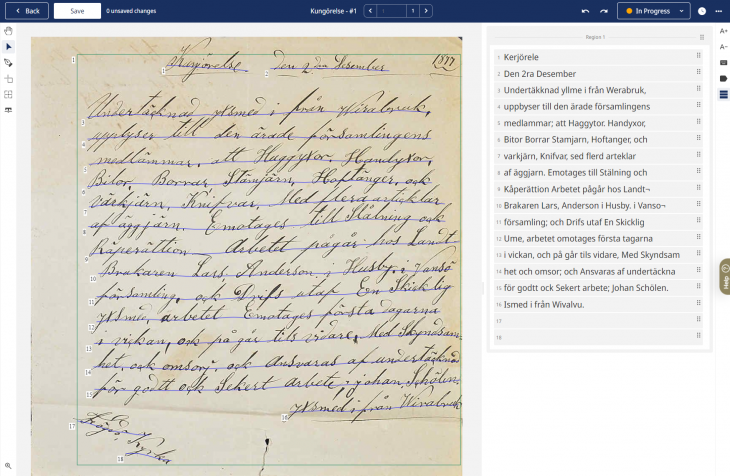
Du ska då få upp en bild med dokumentet och den tolkade texten till höger.

Redigera den tolkade texten
HTR-modellen kommer inte att lyckas med att tolka all text exakt rätt. Den tolkade texten till höger går dock att redigera så det blir som du tycker att det egentligen står i dokumentet.
Grundprincipen är en eller flera ”Regions” – för en textsida eller de textdelar som man vill hålla isär (t.ex. löptext, rubrik, paginering, marginalanteckningar) – och inom varje ”Region” finns ”Lines” för varje textrad. Det finns en rad olika snabbkommandon för att redigera Regions och Lines.
Bekanta dig med dessa i hjälpen: https://help.transkribus.org/manual-layout-editing.
Uppe till vänster i menyraden har du knappen Save för att spara dina ändringar i den ändrade texten. Klicka på den så att dina ändringar sparas.
Uppe till höger har du en vallista med olika statusar på ditt arbete. Ett nytolkat dokument får statusen “In Progress", du kan sen själv välja bland ytterligare några andra statusar.
Dela med dig av den tolkade texten
När du känner att den tolkade texten är mer eller mindre “korrekt” utefter vad du har för behov och syfte med texttolkningen så kan du dela med dig av texten på olika sätt.
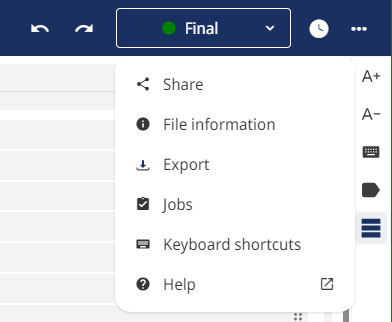
Share - Här skapas en publicering på webben och du får en URL länk som du kan skicka till andra.
File information - Du kan lägga in olika egenskaper på dokumentet.
Export - Du kan exportera dels bilddokumentet och dels den tolkade texten. Den tolkade texten kan exporteras dels som XML och dels som textfil.
Jobs - Du öppnar jobblistan.
Keyboard shortcuts - Lista med tillgängliga tangentbords kommandon.
Help - Transkribus hjälp.
Riksarkivet - HTRFLOW
HTRFLOW - a Hugging Face Space by Riksarkivet
HTRFLOW är Riksarkivets egen applikation för texttolkning via “The Swedish Lion” modellen. Den är något enklare i sitt utförande. Den har dock inte samma kapacitet för tillfället som Transkribus har så det kan bli väntetid och ta längre tid. Den är främst gjord för demonstrationssyfte i olika sammanhang för att förklara processen i texttolkningen.
HTRFLOW har två olika lägen, ett snabbspår och ett som går steg för steg enligt modellen med att först analysera hela dokumentet och hitta olika textregioner. I steg två genomförs textradssegmentering och slutligen i tredje steget körs själva text igenkänningen.
I den här applikationen ser du tydligare hur verktyget arbetar och vilket resultat den får fram i de olika stegen.








